
Economics K-means Clustering Algorithm
The steps are as follows. Integration of K-means into a system using a recommended system by Amin Ramdhani 2006.
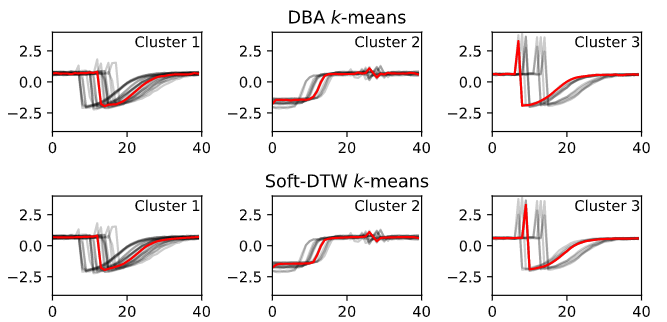
How To Apply K Means Clustering To Time Series Data By Alexandra Amidon Towards Data Science
Using K centroids data is moved from one cluster to another based on similarity.
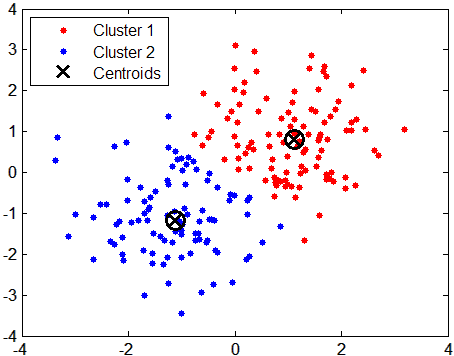
Economics k-means clustering algorithm. K-means is one of the simplest unsupervised learning algorithms that solve the well known clustering problem Kaufman and Rousseeuw 6. Business Administration Ritsumeikan University 2009. In statistics k-medians clustering is a cluster analysis algorithm.
The main reason is its simplicity. K-means clustering is a type of unsupervised learning which is used when you have unlabeled data ie data without defined categories or groups. K-Means Clustering Algorithm is used for clustering and makes clusters of similar data.
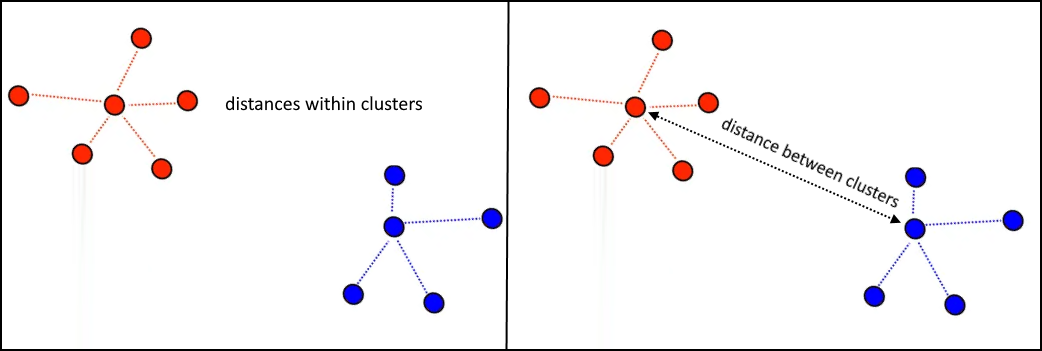
We have explored the K-means clustering algorithm and underwent a journey of inspirational gravity. Algorithm Description What is K-means. There is an algorithm that tries to minimize the distance of the points in a cluster with their centroid the k-means clustering technique.
The unprecedented data volumes require an effective data analysis and prediction platform to achieve fast response and real-time classification for. In this article weve examined how economics and data science could be combined to get a new perspective on pressing issues. Kmeans algorithm is an iterative algorithm that tries to partition the dataset into Kpre-defined distinct non-overlapping subgroups clusters where each data point belongs to only one group.
Predefined clusters are used for data classification. K-Means is a clustering algorithm in machine learning that can group an unlabeled dataset very quickly and efficiently in just a few iterations. It is a variation of k-means clustering where instead of calculating the mean for each cluster to determine its centroid one instead calculates the median.
Algorithm that is based on clustering the data into local regions is the K-means algorithm MacQueen 5. Clustering is dividing data into groups based on similarity. By umar Published September 15 2021 Updated September 19 2021.
K-means is clustering algorithm that devides each data item into a cluster. Analysis of high-dimensional economic big data based on innovative distributed feature selection to STC and K-means Clustering Algorithm. In this tutorial well start with the theoretical foundations of the K-means algorithm well discuss how it works and what pitfalls to avoid.
When the instances are centred around a particular point that point is called a centroid. Number of clusters K must be specified Algorithm Statement Basic Algorithm of K-means. There are many different types of clustering methods but k -means is one of the oldest and most approachable.
As k increases you need advanced versions of k-means to pick better values of the initial centroids called k-means seeding. Define a number of cluster k at data set. K-Means Clustering - K-means clustering is one of the simplest and popular unsupervised machine learning algorithms.
K-Means Clustering Algorithm. However it comes with the following potential drawbacks. It works by labelling all instances on the cluster with the closest centroid.
And K-means is one of the most commonly used methods in clustering. K-means clustering is a very classical clustering algorithm and it is also one of the representatives of unsupervised learning. Pros Cons of K-Means Clustering.
Its sensitive to outliers. The k-means clustering method is an unsupervised machine learning technique used to identify clusters of data objects in a dataset. It tries to make the intra-cluster data points as similar as possible while also keeping the clusters as different far as possible.
First we initialize k points called means randomly. The goal of this algorithm is to find groups in the data with the number of groups represented by the variable K. Each point is assigned to the cluster with the closest centroid 4 Number of clusters K must be specified4.
K-means is an iterative. Robustification of the sparse K-means clustering algorithm by Yumi Kondo BS. It has the advantages of a simple idea high efficiency and easy implementation so it is widely used in many fields.
But the ever-emerging data with extremely complicated characteristics bring new challenges to this old algorithm. It can handle large datasets well. K-means clustering offers the following benefits.
Nearly everyone knows K-means algorithm in the fields of data mining and business intelligence. This book addresses these challenges and makes novel contributions in establishing theoretical frameworks for K-means distances and K-means based consensus clustering. For a full discussion of k- means seeding see A Comparative Study of Efficient Initialization Methods for the K-Means Clustering Algorithm by M.
K-means is one of a clustering algorithm which uses partition method. Of course there are many more clustering algorithms out there. The principle of the k-means algorithm is to find the following cluster centers and sets of elements of each cluster in the presence of some function F which express- es the quality of the current division of the set into k clusters when the total quadratic.
It requires us to specify the number of clusters before performing the algorithm. The algorithm works as follows. Emre Celebi Hassan A.
Economics American University 2009 BA. It is a fast algorithm. Partitional clustering approach 2.
Each cluster is associated with a centroid center point 3. Such as DBSCAN Affinity Propagation MeanShit and so on.

Using K Means Clustering With Tensorflow Distributed Computing Learning Methods Deep Learning

Cluster Analysis 1
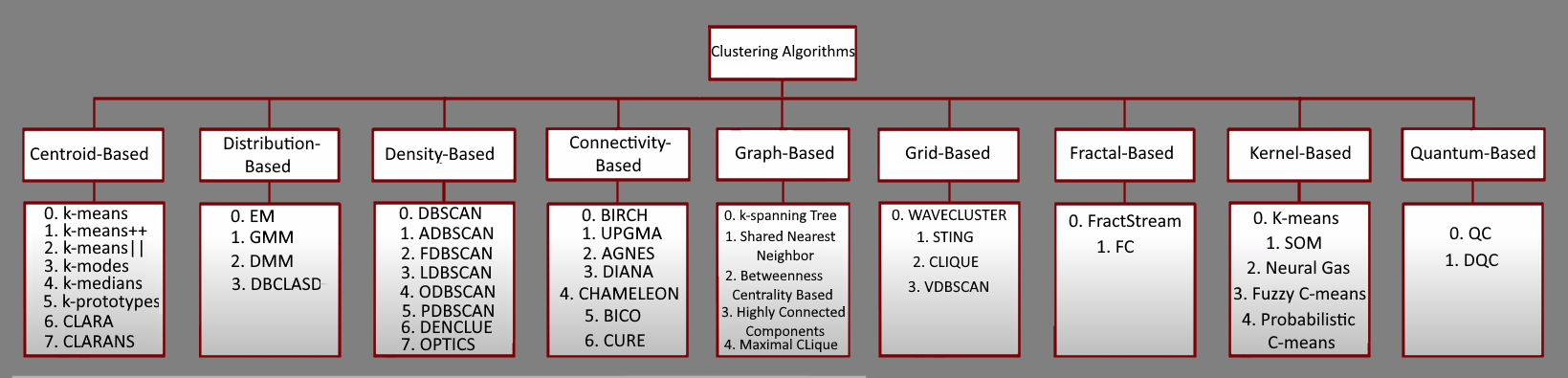
17 Clustering Algorithms Used In Data Science And Mining By Mahmoud Harmouch Towards Data Science

Pdf Parallelizing K Means Based Clustering On Spark

Pdf Parallelizing K Means Based Clustering On Spark
17 Clustering Algorithms Used In Data Science And Mining By Mahmoud Harmouch Towards Data Science
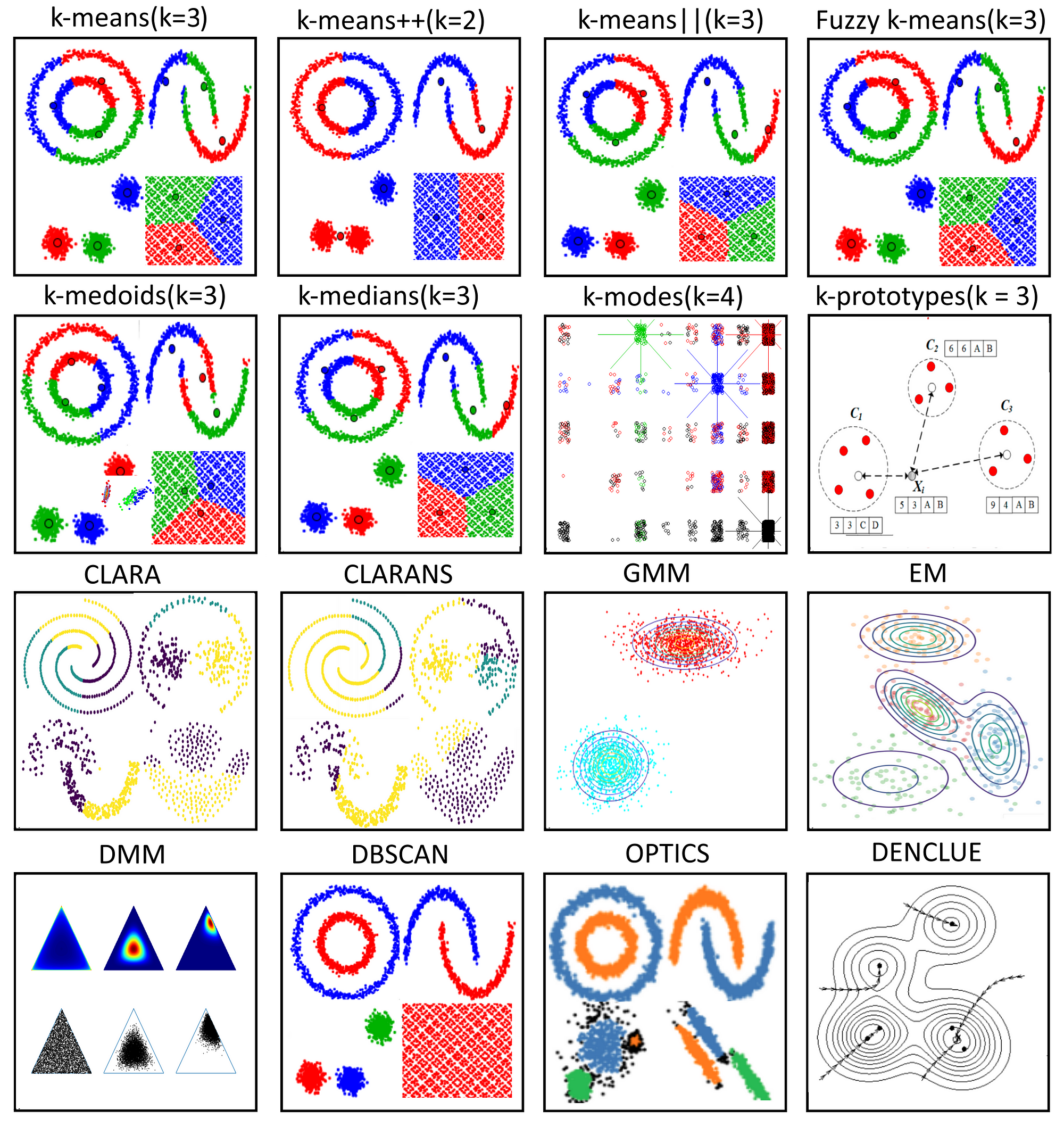
17 Clustering Algorithms Used In Data Science And Mining By Mahmoud Harmouch Towards Data Science
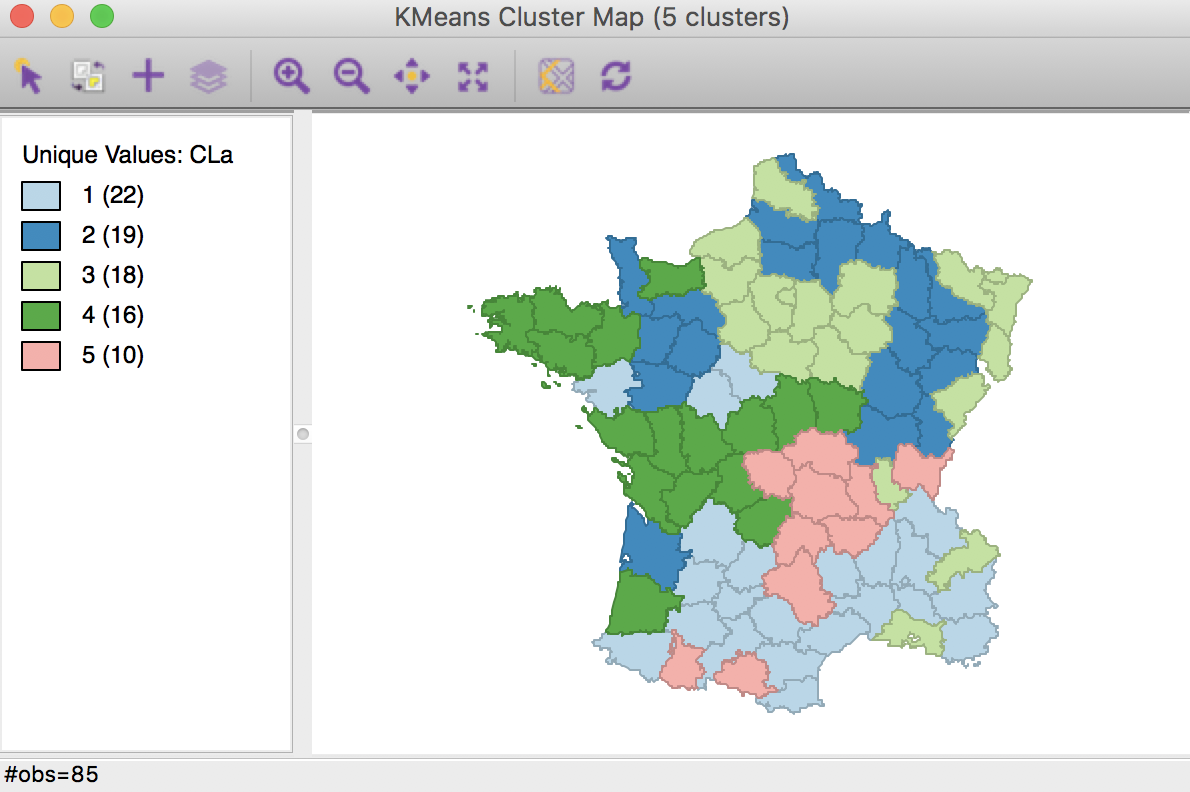
Cluster Analysis 1

17 Clustering Algorithms Used In Data Science And Mining By Mahmoud Harmouch Towards Data Science
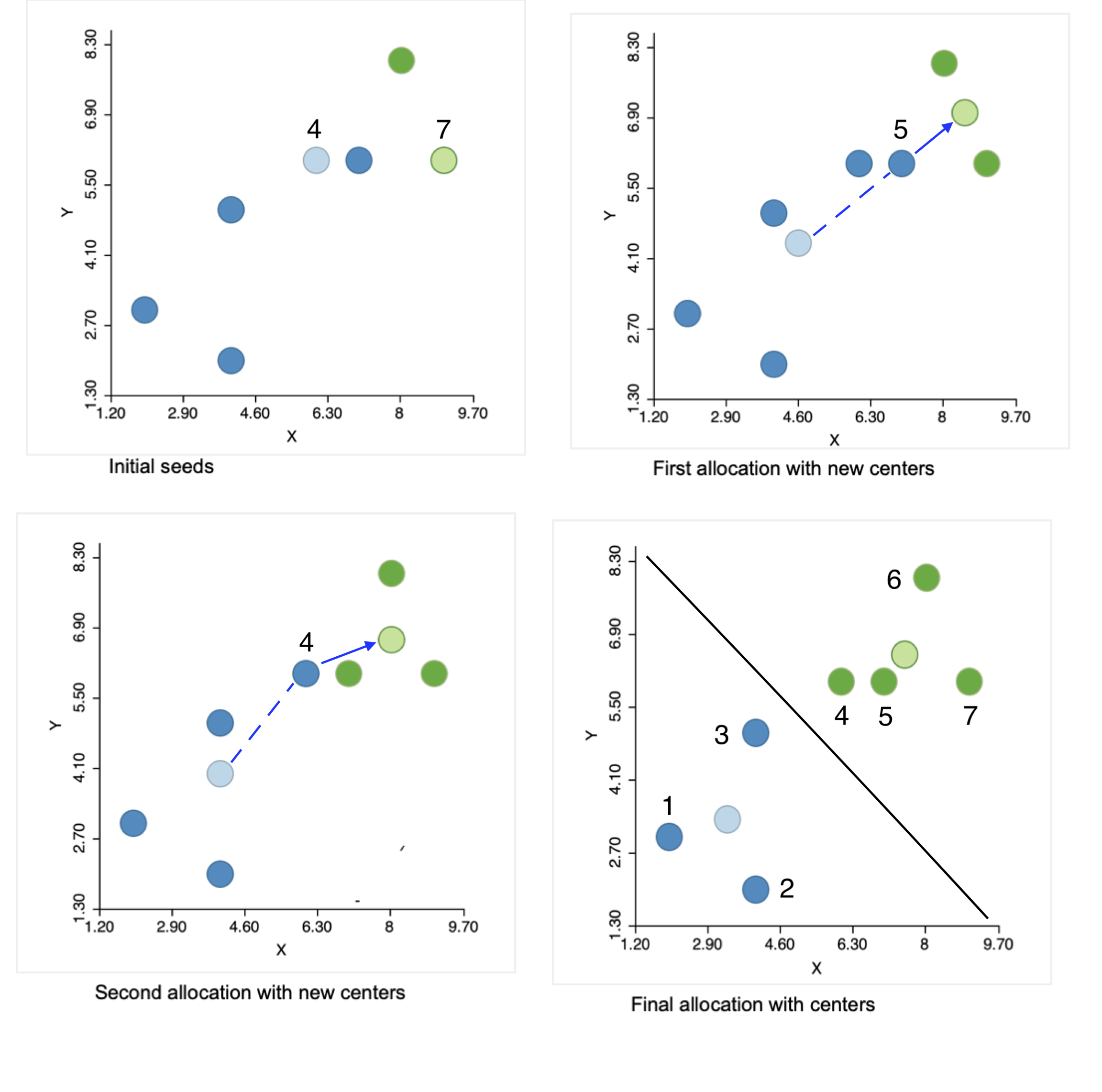
Cluster Analysis 1

Pdf Cluster Analysis Overview
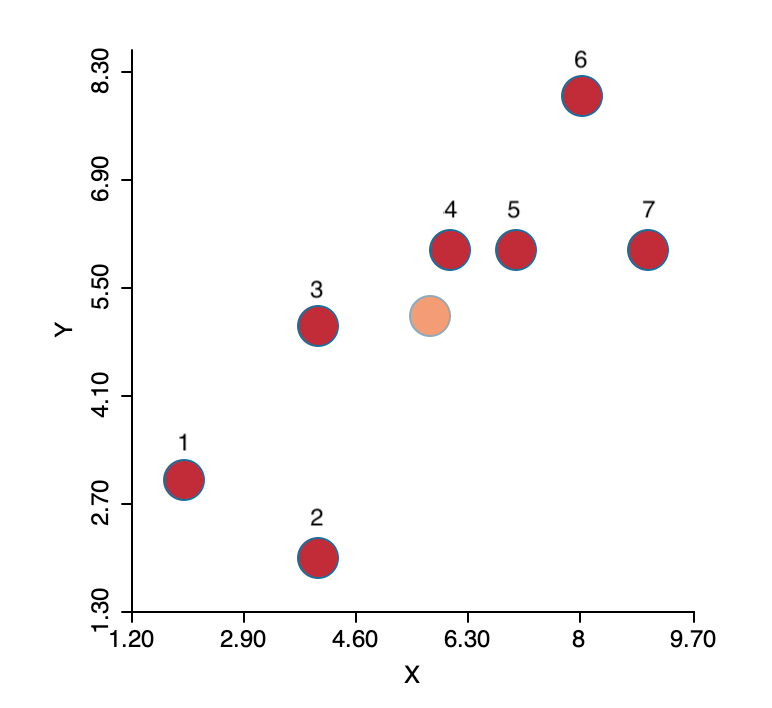
Cluster Analysis 1
Sensors Free Full Text Multiple Electric Energy Consumption Forecasting Using A Cluster Based Strategy For Transfer Learning In Smart Building Html
10 Interesting Use Cases For The K Means Algorithm Dzone Ai
{kind=link}
Posting Komentar untuk "Economics K-means Clustering Algorithm"